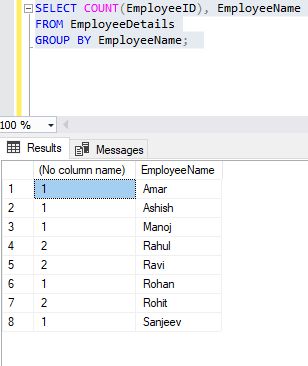
La clause GROUP BY est une commande SQL utilisée pour regrouper des lignes ayant les mêmes valeurs. La clause GROUP BY est utilisée dans l’instruction SELECT. En option, il est utilisé conjointement avec des fonctions d’agrégation pour produire des rapports de synthèse à partir de la base de données. C’est ce qu’il fait, en résumant les données de la base de données.vor 6 Tagen
Qu’est-ce que GROUP BY dans une requête SQL ?
L’instruction GROUP BY regroupe les lignes qui ont les mêmes valeurs dans des lignes récapitulatives, comme « trouver le nombre de clients dans chaque pays ». L’instruction GROUP BY est souvent utilisée avec les fonctions d’agrégation ( COUNT() , MAX() , MIN() , SUM() , AVG() ) pour regrouper le jeu de résultats par une ou plusieurs colonnes.
Pouvons-nous utiliser SELECT avec GROUP BY ?
Vous pouvez utiliser une commande SELECT avec une clause GROUP BY pour regrouper toutes les lignes qui ont des valeurs identiques dans une colonne ou une combinaison de colonnes spécifiée, en une seule ligne. Vous pouvez également trouver la valeur agrégée pour chaque groupe de valeurs de colonne.
Quelle est la différence entre ORDER BY et GROUP BY dans l’instruction SQL SELECT ?
L’instruction Group by est utilisée pour regrouper les lignes qui ont la même valeur. Tandis que l’instruction Order by trie le jeu de résultats par ordre croissant ou décroissant.
Quelle est la différence entre SELECT distinct et GROUP BY ?
La principale différence entre DISTINCT et GROUP BY est que l’opérateur GROUP BY est destiné aux lignes d’agrégation ou de regroupement, tandis que DISTINCT est simplement utilisé pour obtenir des valeurs distinctes.
Qu’est-ce que GROUP BY dans une requête SQL ?
L’instruction GROUP BY regroupe les lignes qui ont les mêmes valeurs dans des lignes récapitulatives, comme « trouver le nombre de clients dans chaque pays ». L’instruction GROUP BY est souvent utilisée avec les fonctions d’agrégation ( COUNT() , MAX() , MIN() , SUM() , AVG() ) pour regrouper le jeu de résultats par une ou plusieurs colonnes.
Pouvons-nous utiliser SELECT avecGROUPER PAR ?
Vous pouvez utiliser une commande SELECT avec une clause GROUP BY pour regrouper toutes les lignes qui ont des valeurs identiques dans une colonne ou une combinaison de colonnes spécifiée, en une seule ligne. Vous pouvez également trouver la valeur agrégée pour chaque groupe de valeurs de colonne.
GROUP BY supprime-t-il les doublons ?
GROUP BY ne traite que deux lignes comme doublons si toutes les valeurs de colonne des deux lignes sont identiques. Si même une seule valeur de colonne dans l’une ou l’autre des lignes ne correspond pas, elles sont traitées comme uniques.
GROUP BY est-il plus rapide que SELECT ?
GROUP BY est légèrement plus rapide que SELECT DISTINCT Plus le lecteur est lent, plus la différence est grande.
Pourquoi ai-je besoin de GROUP BY SQL ?
Group by est l’une des clauses SQL les plus fréquemment utilisées. Il vous permet de réduire un champ à ses valeurs distinctes. Cette clause est le plus souvent utilisée avec des agrégations pour afficher une valeur par champ groupé ou combinaison de champs. Nous pouvons utiliser un groupe SQL par et des agrégats pour collecter plusieurs types d’informations.
Puis-je utiliser GROUP BY dans une sous-requête ?
La commande GROUP BY peut être utilisée pour exécuter la même fonction que ORDER BY dans une sous-requête. Les sous-requêtes qui renvoient plus d’une ligne ne peuvent être utilisées qu’avec plusieurs opérateurs de valeurs tels que l’opérateur IN.
Qu’est-ce qui exécute en premier SELECT ou GROUP BY ?
Points importants : la clause GROUP BY est utilisée avec l’instruction SELECT. Dans la requête, la clause GROUP BY est placée après la clause WHERE. Dans la requête, la clause GROUP BY est placée avant la clause ORDER BY si elle est utilisée.
GROUP BY supprime-t-il les doublons dans SQL ?
SQL Supprimer les lignes en double à l’aide de Group By et d’avoir la clause Selon Supprimer les lignes en double dans SQL, pour trouver des lignes en double, vous devez utiliser la clause SQL GROUP BY. La fonction COUNT peut être utilisée pour vérifier l’occurrence d’une ligne à l’aide de laClause Group by, qui regroupe les données en fonction des colonnes données.
Quel est l’avantage de GROUP BY en SQL ?
Group by est l’une des clauses SQL les plus fréquemment utilisées. Il vous permet de réduire un champ à ses valeurs distinctes. Cette clause est le plus souvent utilisée avec des agrégations pour afficher une valeur par champ groupé ou combinaison de champs. Nous pouvons utiliser un groupe SQL par et des agrégats pour collecter plusieurs types d’informations.
GROUP BY est-il nécessaire en SQL ?
GROUP BY en SQL, expliqué Et l’agrégation de données est impossible sans GROUP BY ! Par conséquent, il est important de maîtriser GROUP BY pour effectuer facilement tous les types de transformations et d’agrégations de données. En SQL, GROUP BY est utilisé pour l’agrégation de données, à l’aide de fonctions d’agrégation.
Qu’est-ce que GROUP BY dans la fonction d’agrégat ?
L’instruction Group By est utilisée pour regrouper toutes les lignes d’une colonne contenant la même valeur, en fonction d’une fonction spécifiée dans l’instruction. Généralement, ces fonctions font partie des fonctions d’agrégation telles que MAX() et SUM().
Qu’est-ce que GROUP BY dans une requête SQL ?
L’instruction GROUP BY regroupe les lignes qui ont les mêmes valeurs dans des lignes récapitulatives, comme « trouver le nombre de clients dans chaque pays ». L’instruction GROUP BY est souvent utilisée avec les fonctions d’agrégation ( COUNT() , MAX() , MIN() , SUM() , AVG() ) pour regrouper le jeu de résultats par une ou plusieurs colonnes.
Pouvons-nous utiliser SELECT avec GROUP BY ?
Vous pouvez utiliser une commande SELECT avec une clause GROUP BY pour regrouper toutes les lignes qui ont des valeurs identiques dans une colonne ou une combinaison de colonnes spécifiée, en une seule ligne. Vous pouvez également trouver la valeur agrégée pour chaque groupe de valeurs de colonne.
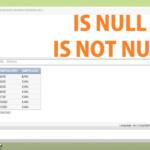
GROUP BY prend-il des valeurs nulles ?
GROUP BY traite toutes les valeurs NULL de la même manière.
Comment éviter les doublons en SQL ?
Si vous voulez que lequery pour ne renvoyer que des lignes uniques, utilisez le mot-clé DISTINCT après SELECT . DISTINCT peut être utilisé pour extraire des lignes uniques d’une ou plusieurs colonnes. Vous devez répertorier les colonnes après le mot-clé DISTINCT.
Comment gérez-vous GROUP BY Null ?
Si la colonne de regroupement contient une valeur nulle, cette ligne devient son propre groupe dans les résultats. Si la colonne de regroupement contient plusieurs valeurs nulles, toutes les valeurs nulles forment un seul groupe.
Quel type de données est le plus rapide en SQL ?
Pour accélérer les tris fréquents, utilisez si possible un type de données int (ou un type de données entier). SQL Server trie les données entières plus rapidement que les données caractères.