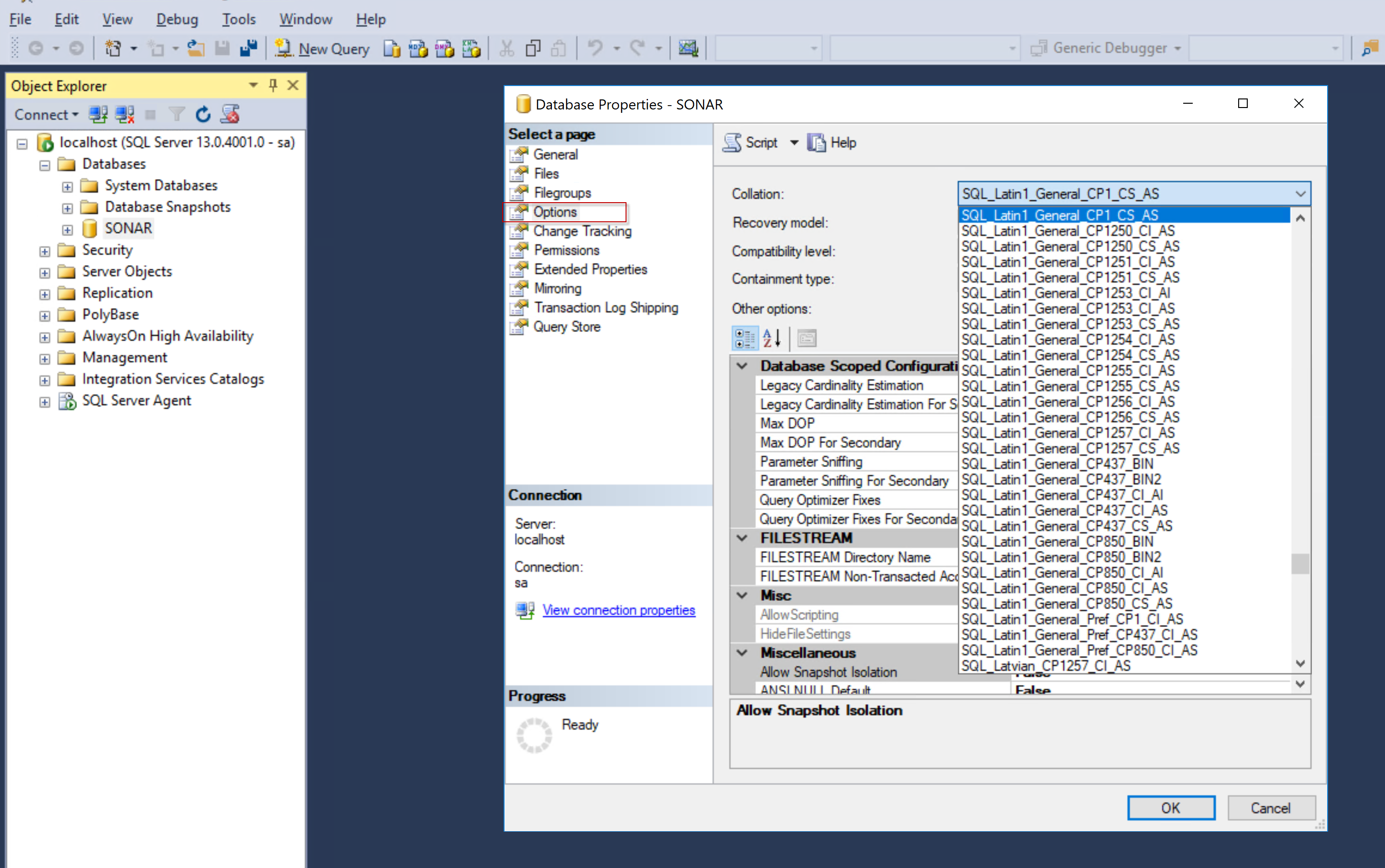
Le classement SQL_Latin1_General_CP1_CI_AS est un classement SQL et les règles de tri des données pour les données Unicode et non Unicode sont différentes. Le classement Latin1_General_CI_AS est un classement Windows et les règles de tri des données unicode et non-unicode sont les mêmes.
Que signifie SQL_Latin1_General_CP1_CI_AS ?
La clause collate est utilisée pour les recherches sensibles et insensibles à la casse dans les colonnes du serveur SQL. Il existe deux types de clause d’assemblage : SQL_Latin1_General_CP1_CS_AS pour la sensibilité à la casse. SQL_Latin1_General_CP1_CI_AS pour insensible à la casse.
SQL_Latin1_General_CP1_CI_AS est-il obsolète ?
Latin1_General_CI_AS est-il sensible à la casse ?
Dans SQL Server, les options de classement sont spécifiées en ajoutant les options au nom du classement. Ainsi, par exemple, Latin1_General_CI_AS est insensible à la casse et aux accents.
Quel classement dois-je utiliser pour SQL Server ?
Classement au niveau du serveur pour Microsoft SQL Server Si vous ne choisissez pas un classement différent, le classement au niveau du serveur est par défaut SQL_Latin1_General_CP1_CI_AS. Le classement du serveur est appliqué par défaut à toutes les bases de données et objets de base de données.
Quel jeu de caractères est SQL_Latin1_General_CP1_CI_AS ?
SQL_Latin1_General_CP1_CI_AS = ‘Ordre du dictionnaire, insensible à la casse, à utiliser avec un jeu de caractères de 1252.
Qu’est-ce qu’une page de codes pour SQL_Latin1_General_CP1_CI_AS ?
Utilisez l’une ou l’autre des pages de codes : « Latin1_General_CI_AS » « SQL_Latin1_General_CP1_CI_AS » (CP 1252)
Le classement est-il important en SQL ?
Les données suivent toujours les règles de contrainte de classement, qui sont configurées lors de la création d’un objet. Lors de la récupération de données à l’aide d’une requête T-SQL, le classement joue un rôle fondamental dans l’exécution. Il est important de savoir quel classement est associé à une colonne lors de la commande de la clauseest appliqué à cette colonne.
Puis-je modifier le classement SQL Server après l’installation ?
Le classement au niveau du serveur pour SQL Server Express LocalDB est SQL_Latin1_General_CP1_CI_AS et ne peut pas être modifié, ni pendant ni après l’installation.
Quels sont les différents types de sensibilité au classement ?
Les options associées à un classement sont la sensibilité à la casse, la sensibilité aux accents, la sensibilité au kana, la sensibilité à la largeur et la sensibilité au sélecteur de variation.
Qu’est-ce que le classement par défaut d’Oracle ?
Collation binaire Il s’agit d’une collation par défaut de la session de base de données pour ORDER BY et BETWEEN (et d’autres opérations qui prennent en charge le tri linguistique) et est défini comme « binaire » dans la variable NLS_COMP.
Les Guids doivent-ils être en majuscules ou en minuscules ?
Le Guid lui-même est en fait une valeur entière de 128 bits et la chaîne est une représentation hexadécimale de la même valeur et l’hexadécimal n’est pas sensible à la casse.
Le classement affecte-t-il les performances ?
Si vous spécifiez ensuite une clause COLLATE dans la requête qui est différente de la collation utilisée pour l’index, vous subirez une baisse des performances car vous n’utiliserez pas cet index.
Quel classement est le meilleur dans MySQL ?
Si vous choisissez d’utiliser UTF-8 comme classement, utilisez toujours utf8mb4 (en particulier utf8mb4_unicode_ci). Vous ne devez pas utiliser UTF-8 car l’UTF-8 de MySQL est différent de l’encodage UTF-8 approprié. C’est le cas car il n’offre pas de prise en charge complète de l’unicode, ce qui peut entraîner des pertes de données ou des problèmes de sécurité.
Que signifie un %’ en SQL ?
L’opérateur SQL LIKE Le signe de pourcentage (%) représente zéro, un ou plusieurs caractères. Le signe de soulignement (_) représente un seul caractère.
Pourquoi le classement est-il utilisé ?
Les classements dans SQL Server fournissent des règles de tri, des propriétés de sensibilité à la casse et aux accents pour votreLes données. Les classements utilisés avec les types de données de caractères, tels que char et varchar, dictent la page de codes et les caractères correspondants qui peuvent être représentés pour ce type de données.
Pourquoi utilisons-nous le classement ?
Les collections sont utilisées pour stocker, récupérer, manipuler et communiquer des données agrégées. En règle générale, ils représentent des éléments de données qui forment un groupe naturel, comme une main de poker (une collection de cartes), un dossier de courrier (une collection de lettres) ou un annuaire téléphonique (une mise en correspondance de noms avec des numéros de téléphone).
Pourquoi avons-nous besoin d’un classement ?
Un classement permet de trier les données de caractères d’une langue donnée à l’aide de règles définissant la séquence de caractères correcte, avec des options permettant de spécifier la sensibilité à la casse, les accents, les types de caractères kana, l’utilisation de symboles ou de ponctuation, la largeur des caractères et le mot tri.
Quelle est la différence entre utf8_general_ci et utf8_unicode_ci ?
En bref : utf8_unicode_ci utilise l’algorithme de classement Unicode tel que défini dans les normes Unicode, tandis que utf8_general_ci est un ordre de tri plus simple qui donne des résultats de tri « moins précis ». Si vous ne vous souciez pas de l’exactitude, alors il est trivial de rendre n’importe quel algorithme infiniment rapide.
Qu’est-ce que le classement UTF8 ?
Un classement est une propriété des types de chaîne dans SQL Server, Azure SQL et Synapse SQL qui définit comment comparer et trier les chaînes. De plus, il décrit le codage des données de chaîne. Si un nom de classement dans Synapse SQL se termine par UTF8, il représente les chaînes codées avec le schéma de codage UTF-8.
Que signifie UTF-8 ?
UTF-8 (UCS Transformation Format 8) est le codage de caractères le plus courant du World Wide Web. Chaque caractère est représenté par un à quatre octets. UTF-8 est rétrocompatible avec ASCII et peut représenter n’importe quel standard Unicodecaractère.
Quel devrait être le classement de la base de données ?
Le classement est un ensemble de règles qui indiquent au moteur de base de données comment comparer et trier les données de caractères dans SQL Server. Le classement peut être défini à différents niveaux dans SQL Server.