Anúncios
La documentation recommande SQL_Latin1_General_CP1_CI_AS comme page de code recommandée. En règle générale, chaque nombre représente la valeur binaire dans un seul octet.https://en.wikipedia.org › wiki › Code_pageCode page – Wikipedia, mais cela est maintenant considéré comme obsolète dans les nouvelles versions de MS SQL Server.
Est Latin1_General_CI_AS identique à SQL_Latin1_General_CP1_CI_AS ?
Le classement SQL_Latin1_General_CP1_CI_AS est un classement SQL et les règles de tri des données pour les données unicode et non-unicode sont différentes. Le classement Latin1_General_CI_AS est un classement Windows et les règles de tri des données unicode et non-unicode sont les mêmes.
Anúncios
Que signifie le As dans le classement par défaut SQL_Latin1_General_CP1_CI_AS ?
Le classement du serveur est spécifié lors de l’installation de SQL Server. Le classement par défaut au niveau du serveur est basé sur les paramètres régionaux du système d’exploitation. Par exemple, le classement par défaut pour les systèmes utilisant l’anglais américain (en-US) est SQL_Latin1_General_CP1_CI_AS.
Quel classement dois-je utiliser pour SQL Server ?
Classement au niveau du serveur pour Microsoft SQL Server Si vous ne choisissez pas un classement différent, le classement au niveau du serveur est par défaut SQL_Latin1_General_CP1_CI_AS. Le classement du serveur est appliqué par défaut à toutes les bases de données et objets de base de données.
Anúncios
Le classement est-il important en SQL ?
Les données suivent toujours les règles de contrainte de classement, qui sont configurées lors de la création d’un objet. Lors de la récupération de données à l’aide d’une requête T-SQL, le classement joue un rôle fondamental dans l’exécution. Il est important de savoir quel classement est associé à une colonne lorsque la clause de commande est appliquée àcette colonne.
Latin1_General_CI_AS est-il identique à SQL_Latin1_General_CP1_CI_AS ?
Le classement SQL_Latin1_General_CP1_CI_AS est un classement SQL et les règles de tri des données pour les données unicode et non-unicode sont différentes. Le classement Latin1_General_CI_AS est un classement Windows et les règles de tri des données unicode et non-unicode sont les mêmes.
SQL_Latin1_General_CP1_CI_AS est-il sensible à la casse ?
Classement de la base de données Par exemple, le classement par défaut au niveau du serveur dans SQL Server pour les paramètres régionaux de la machine « Anglais (États-Unis) » est SQL_Latin1_General_CP1_CI_AS , qui est un classement insensible à la casse et aux accents.
Quel jeu de caractères est SQL_Latin1_General_CP1_CI_AS ?
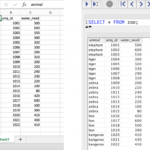
SQL_Latin1_General_CP1_CI_AS = ‘Ordre du dictionnaire, insensible à la casse, à utiliser avec un jeu de caractères de 1252.
Le classement affecte-t-il les performances ?
Si vous spécifiez ensuite une clause COLLATE dans la requête qui est différente de la collation utilisée pour l’index, vous subirez une baisse des performances car vous n’utiliserez pas cet index.
L’UTF-8 inclut-il Latin1 ?
L’alphabet chinois et d’autres n’utilisent pas du tout le latin1. Ces caractères et symboles font partie d’un système de codage beaucoup plus vaste appelé UTF8, qui inclut également Latin1.
Pourquoi avons-nous besoin d’un classement ?
Un classement permet de trier les données de caractères d’une langue donnée à l’aide de règles définissant la séquence de caractères correcte, avec des options permettant de spécifier la sensibilité à la casse, les accents, les types de caractères kana, l’utilisation de symboles ou de ponctuation, la largeur des caractères et le mot tri.
Les majuscules sont-elles importantes en SQL ?
Les mots-clés en SQL sont insensibles à la casse pour les SGBD les plus populaires. L’ordinateur ne se soucie pas de savoir si vous écrivez SELECT , select ou sELeCt ; donc, en théorie, vous pouvez écrire comme bon vous semble.
Quoiest la différence entre classement et collecte ?
La différence est que la collecte est un ensemble d’articles ou une quantité de matériel acheté ou rassemblé pendant que la collecte rassemble.
Quelle est la différence entre Vachar et Nvarchar ?
La principale différence entre varchar et nvarchar est la façon dont ils sont stockés, varchar est stocké sous forme de données 8 bits normales (1 octet par caractère) et nvarchar stocke les données à 2 octets par caractère. Pour cette raison, nvarchar peut contenir jusqu’à 4000 caractères et prend le double d’espace comme SQL varchar.
Quelle est la différence entre GAM et SGAM dans SQL Server ?
C’est-à-dire qu’une page GAM peut contenir des informations de (64000X8X8)/1024 = 4000 Mo environ. En bref, un fichier de données de taille 7 Go aura deux pages GAM. SGAM (Shares Global Allocation Map) : les pages SGAM enregistrent les étendues actuellement utilisées comme étendues mixtes et comportent également au moins une page inutilisée.
Qu’est-ce que le classement de base de données ?
Les classements dans SQL Server fournissent des règles de tri, des propriétés de sensibilité à la casse et aux accents pour vos données. Les classements utilisés avec les types de données de caractères, tels que char et varchar, dictent la page de codes et les caractères correspondants qui peuvent être représentés pour ce type de données.
Qu’est-ce que SqlException 0x80131904 ?
SqlException (0x80131904) : le délai de connexion a expiré. Le délai d’expiration s’est écoulé pendant la phase de post-connexion. La connexion a peut-être expiré en attendant que le serveur termine le processus de connexion et réponde ; Ou il peut avoir expiré lors de la tentative de création de plusieurs connexions actives.
Latin1_General_CI_AS est-il identique à SQL_Latin1_General_CP1_CI_AS ?
Le classement SQL_Latin1_General_CP1_CI_AS est un classement SQL et les règles de tri des données pour les données unicode et non-unicode sont différentes. LaLe classement Latin1_General_CI_AS est un classement Windows et les règles de tri des données unicode et non-unicode sont les mêmes.
Quelle est la meilleure défense de l’injection SQL ?
Échappement de caractères L’échappement de caractères est un moyen efficace d’empêcher l’injection SQL. Caractères spéciaux comme « / — sont interprétés par le serveur SQL comme une syntaxe et peuvent être traités comme une attaque par injection SQL lorsqu’ils sont ajoutés dans le cadre de l’entrée.
Qu’est-ce qui est le plus vulnérable aux attaques par injection SQL ?
La plupart des vulnérabilités d’injection SQL surviennent dans la clause WHERE d’une requête SELECT. Ce type d’injection SQL est généralement bien compris par les testeurs expérimentés. Mais les vulnérabilités d’injection SQL peuvent en principe se produire à n’importe quel endroit de la requête, et dans différents types de requêtes.
Les rançongiciels affectent-ils SQL Server ?
Le ransomware crypte certains fichiers et en évite d’autres, y compris les fichiers avec une extension associée à ses propres activités (. FARGO, . FARGO2, etc.) et celle de GlobeImposter, une autre menace de ransomware ciblant les serveurs MS SQL vulnérables.
Le WE8ISO8859P1 est-il multioctet ?
WE8ISO8859P1 est un octet unique et peut stocker des caractères européens. UTF8 est multi-octets et peut stocker d’autres caractères, y compris le japonais, le chinois, etc.