Anúncios
Le regole di confronto in SQL Server forniscono regole di ordinamento, maiuscole e minuscole e proprietà di sensibilità all’accento per i dati. Le regole di confronto utilizzate con i tipi di dati carattere, come char e varchar, determinano la tabella codici e i caratteri corrispondenti che possono essere rappresentati per quel tipo di dati.
Cos’è l’errore di confronto in SQL?
Cos’è il confronto del server in SQL Server?
Le regole di confronto in SQL Server sono un insieme predefinito di regole che determinano la modalità di salvataggio, accesso e confronto dei dati. In altre parole, è un’impostazione di configurazione che indica come il motore del database dovrebbe gestire i dati dei caratteri.
Anúncios
Che cos’è la raccolta SQL_Latin1_General_CP1_CI_AS in SQL Server?
La clausola collate viene utilizzata per ricerche con distinzione tra maiuscole e minuscole nelle colonne del server SQL. Sono presenti due tipi di clausola fascicolazione: SQL_Latin1_General_CP1_CS_AS per la distinzione tra maiuscole e minuscole. SQL_Latin1_General_CP1_CI_AS per maiuscole e minuscole.
Come ottengo le regole di confronto in SQL Server?
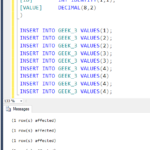
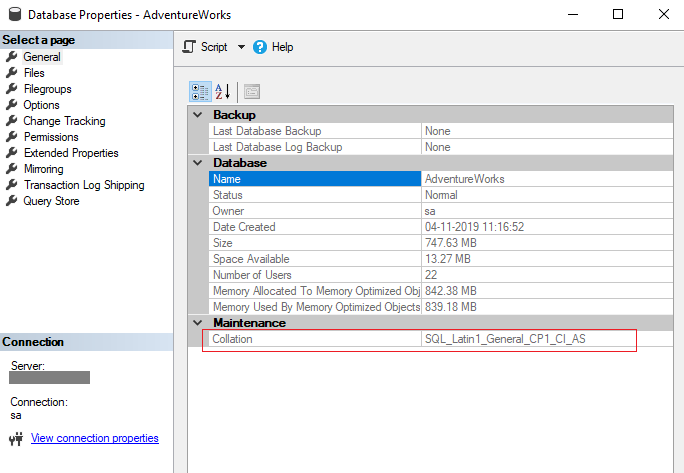
Per visualizzare l’impostazione delle regole di confronto di un database In Esplora oggetti connettersi a un’istanza del Motore di database e sulla barra degli strumenti fare clic su Nuova query. Nella finestra della query, immetti la seguente istruzione che usa sys. visualizzazione del catalogo di sistema dei database. SELECT nome, collation_name FROM sys.
Anúncios
Cos’è l’errore di confronto in SQL?
Come posso modificare le regole di confronto in SQL?
In alternativa, se il database esiste già, fare clic con il pulsante destro del mouse sul database desiderato e selezionare Proprietà. Selezionare la pagina Opzioni e selezionare un confronto dall’elenco a discesa Fascicolazione. Al termine, selezionare OK.
Le regole di confronto influiscono sulle prestazioni?
Se poi specifichi una clausola COLLATE nella query che è diversa dalle regole di confronto utilizzate per l’indice, avrai una riduzione delle prestazioni perchénon utilizzerà quell’indice.
Qual è la differenza tra Latin1_General_CI_AS e SQL_Latin1_General_CP1_CI_AS?
Il confronto SQL_Latin1_General_CP1_CI_AS è un confronto SQL e le regole relative all’ordinamento dei dati Unicode e non Unicode sono diverse. Il confronto Latin1_General_CI_AS è un confronto di Windows e le regole relative all’ordinamento dei dati Unicode e non Unicode sono le stesse.
Cosa significa collazione nel database?
La fascicolazione è un insieme di regole che indicano al motore di database come confrontare e ordinare i dati dei caratteri in SQL Server. Le regole di confronto possono essere impostate a diversi livelli in SQL Server.
Cos’è il processo di raccolta?
La fascicolazione è l’assemblaggio di informazioni scritte in un ordine standard. Molti sistemi di confronto sono basati sull’ordine numerico o alfabetico, o su estensioni e combinazioni degli stessi. La fascicolazione è un elemento fondamentale della maggior parte dei sistemi di archiviazione per ufficio, dei cataloghi delle biblioteche e dei libri di consultazione.
Cosa sono %d e %s in SQL?
Devi usare %d per valori interi e %s per valori stringa. Puoi anche usare %f per un valore in virgola mobile, %b per dati binari e %% solo per inserire un simbolo di percentuale.
Perché si usa la collazione?
Le regole di confronto in SQL Server forniscono regole di ordinamento, maiuscole e minuscole e proprietà di sensibilità all’accento per i dati. Le regole di confronto utilizzate con i tipi di dati carattere, come char e varchar, determinano la tabella codici e i caratteri corrispondenti che possono essere rappresentati per quel tipo di dati.
Perché usiamo la fascicolazione?
È possibile utilizzare la clausola COLLATE per applicare un’espressione di caratteri a un determinato confronto. Ai caratteri letterali e alle variabili vengono assegnate le regole di confronto predefinite del database corrente. Ai riferimenti di colonna vengono assegnate le regole di confronto di definizione della colonna.
Qual è la differenza traLatin1_General_CI_AS e SQL_Latin1_General_CP1_CI_AS?
Il confronto SQL_Latin1_General_CP1_CI_AS è un confronto SQL e le regole relative all’ordinamento dei dati Unicode e non Unicode sono diverse. Il confronto Latin1_General_CI_AS è un confronto di Windows e le regole relative all’ordinamento dei dati Unicode e non Unicode sono le stesse.
Come si risolve Impossibile risolvere il conflitto di regole di confronto tra SQL_Latin1_General_CP1_CI_AS e Latin1_General_CI_AS nell’operazione uguale a?
Problema: impossibile risolvere il conflitto di regole di confronto tra “SQL_Latin1_General_CP1_CI_AS” e “Latin1_General_CI_AS” Basta applicare le regole di confronto predefinite ai campi che stai confrontando.
Cosa significa Norecovery in SQL?
NORECOVERY specifica che il rollback non si verifica. Ciò consente al rollforward di continuare con l’istruzione successiva nella sequenza. In questo caso, la sequenza di ripristino può ripristinare altri backup ed eseguirne il rollforward.
Cos’è l’errore di confronto in SQL?
Qual è la migliore raccolta per MySQL?
Se scegli di utilizzare UTF-8 come regole di confronto, utilizza sempre utf8mb4 (in particolare utf8mb4_unicode_ci). Non dovresti usare UTF-8 perché l’UTF-8 di MySQL è diverso dalla corretta codifica UTF-8. Questo è il caso perché non offre un supporto unicode completo che può portare a perdite di dati o problemi di sicurezza.
SQL_Latin1_General_CP1_CI_AS fa distinzione tra maiuscole e minuscole?
Regole di confronto del database Ad esempio, le regole di confronto predefinite a livello di server in SQL Server per le impostazioni locali del computer “Inglese (Stati Uniti)” sono SQL_Latin1_General_CP1_CI_AS , ovvero regole di confronto senza distinzione tra maiuscole e minuscole e con distinzione dell’accento.
Come si risolve Impossibile risolvere il conflitto di regole di confronto tra SQL_Latin1_General_CP1_CI_AS e Latin1_General_CI_AS nell’operazione uguale a?
Problema: impossibile risolvere il conflitto di regole di confrontotra “SQL_Latin1_General_CP1_CI_AS” e “Latin1_General_CI_AS” Applica semplicemente le regole di confronto predefinite ai campi che stai confrontando.
Qual è la differenza tra Vachar e Nvarchar?
La differenza fondamentale tra varchar e nvarchar è il modo in cui vengono archiviati, varchar viene archiviato come dati regolari a 8 bit (1 byte per carattere) e nvarchar memorizza i dati a 2 byte per carattere. Per questo motivo, nvarchar può contenere fino a 4000 caratteri e occupa il doppio dello spazio di SQL varchar.