Anúncios
Le regole di confronto SQL_Latin1_General_CP1_CI_AS sono regole di confronto SQL e le regole relative all’ordinamento dei dati Unicode e non Unicode sono diverse. Il confronto Latin1_General_CI_AS è un confronto Windows e le regole per l’ordinamento dei dati Unicode e non Unicode sono le stesse.
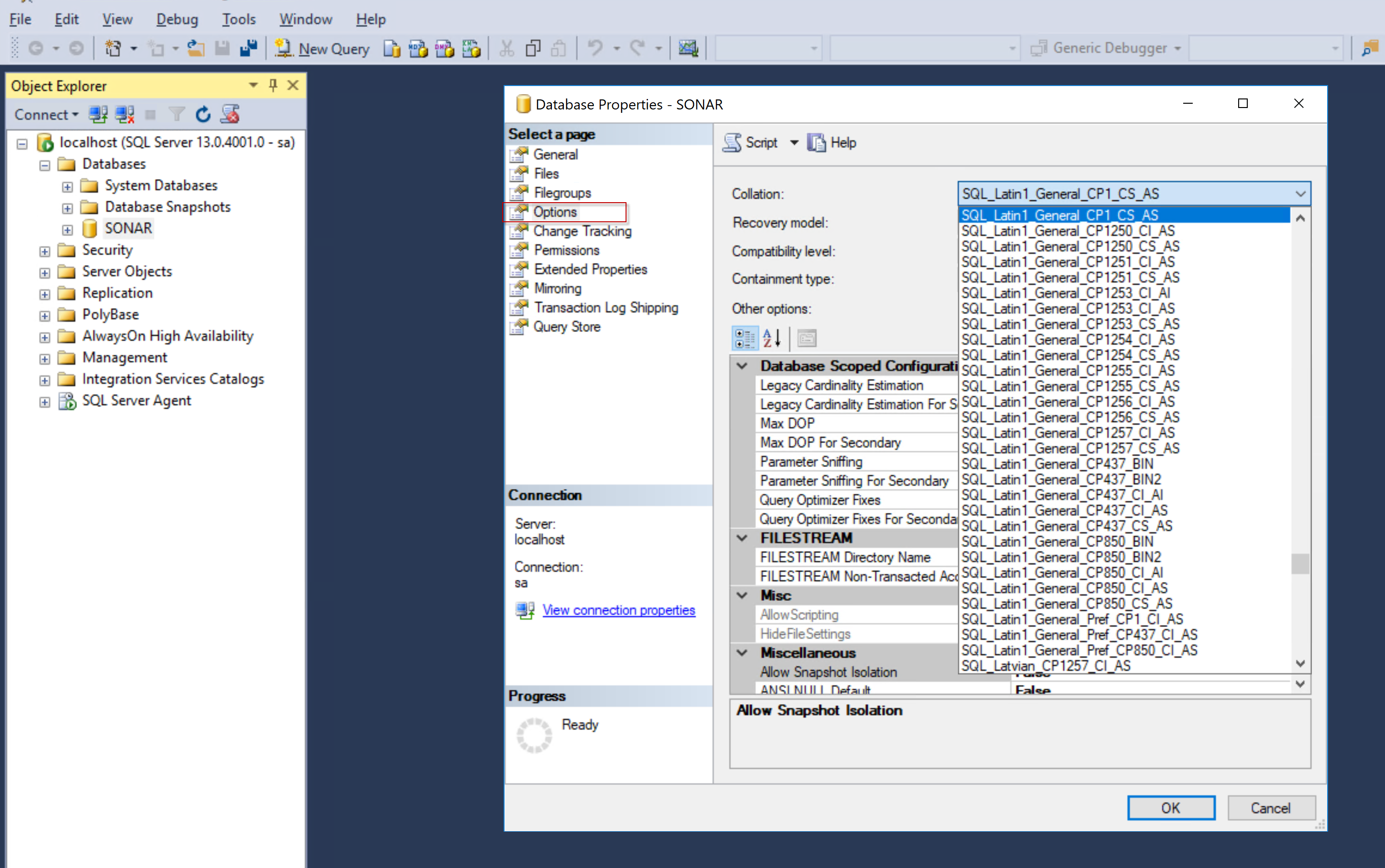
Cosa significa SQL_Latin1_General_CP1_CI_AS?
La clausola collate viene utilizzata per ricerche con distinzione tra maiuscole e minuscole nelle colonne del server SQL. Sono presenti due tipi di clausola fascicolazione: SQL_Latin1_General_CP1_CS_AS per la distinzione tra maiuscole e minuscole. SQL_Latin1_General_CP1_CI_AS per maiuscole e minuscole.
Anúncios
SQL_Latin1_General_CP1_CI_AS è deprecato?
Latin1_General_CI_AS fa distinzione tra maiuscole e minuscole?
In SQL Server, le opzioni di confronto vengono specificate aggiungendo le opzioni al nome del confronto. Quindi, ad esempio, Latin1_General_CI_AS non fa distinzione tra maiuscole e minuscole e non fa distinzione tra maiuscole e minuscole.
Quali regole di confronto devo utilizzare per SQL Server?
Regole di confronto a livello di server per Microsoft SQL Server Se non scegli regole di confronto diverse, le regole di confronto a livello di server vengono impostate per impostazione predefinita su SQL_Latin1_General_CP1_CI_AS. Le regole di confronto del server vengono applicate per impostazione predefinita a tutti i database e gli oggetti di database.
Anúncios
Quale set di caratteri è SQL_Latin1_General_CP1_CI_AS?
SQL_Latin1_General_CP1_CI_AS = ‘Ordine del dizionario, senza distinzione tra maiuscole e minuscole, da utilizzare con set di 1252 caratteri.
Cos’è la tabella codici per SQL_Latin1_General_CP1_CI_AS?
Utilizzare una tabella codici: “Latin1_General_CI_AS” “SQL_Latin1_General_CP1_CI_AS” (CP 1252)
Le regole di confronto sono importanti in SQL?
I dati seguono sempre le regole dei vincoli di confronto, configurate durante la creazione di un oggetto. Quando si recuperano i dati utilizzando una query T-SQL, le regole di confronto svolgono un ruolo fondamentale nell’esecuzione. È importante quale confronto è associato a una colonna quando si ordina la clausolaviene applicato a quella colonna.
Posso modificare le regole di confronto di SQL Server dopo l’installazione?
Le regole di confronto a livello di server per SQL Server Express LocalDB sono SQL_Latin1_General_CP1_CI_AS e non possono essere modificate, né durante né dopo l’installazione.
Quali sono tutti i diversi tipi di sensibilità alle regole di confronto?
Le opzioni associate a una raccolta sono la distinzione tra maiuscole e minuscole, la sensibilità all’accento, la sensibilità al kana, la sensibilità alla larghezza e la sensibilità al selettore di variazione.
Che cos’è la collation predefinita di Oracle?
Binary Collation È una collazione predefinita della sessione del database per ORDER BY e BETWEEN (e altre operazioni che supportano l’ordinamento linguistico) ed è impostata come ‘binary’ nella variabile NLS_COMP.
Le guide devono essere maiuscole o minuscole?
Il Guid stesso è in realtà un valore intero a 128 bit e la stringa è una rappresentazione esadecimale dello stesso valore e l’esadecimale non fa distinzione tra maiuscole e minuscole.
Le regole di confronto influiscono sulle prestazioni?
Se poi specifichi una clausola COLLATE nella query che è diversa dalle regole di confronto utilizzate per l’indice, avrai una riduzione delle prestazioni perché non utilizzerai quell’indice.
Quale confronto è il migliore in MySQL?
Se scegli di utilizzare UTF-8 come regole di confronto, utilizza sempre utf8mb4 (in particolare utf8mb4_unicode_ci). Non dovresti usare UTF-8 perché l’UTF-8 di MySQL è diverso dalla corretta codifica UTF-8. Questo è il caso perché non offre un supporto unicode completo che può portare a perdite di dati o problemi di sicurezza.
Cosa significa %’ in SQL?
L’operatore SQL LIKE Il segno di percentuale (%) rappresenta zero, uno o più caratteri. Il segno di sottolineatura (_) rappresenta un singolo carattere.
Perché si usa la collazione?
Le regole di confronto in SQL Server forniscono regole di ordinamento, maiuscole e minuscole e proprietà di sensibilità all’accento per il filedati. Le regole di confronto utilizzate con i tipi di dati carattere, come char e varchar, determinano la tabella codici e i caratteri corrispondenti che possono essere rappresentati per quel tipo di dati.
Perché usiamo la collazione?
Le raccolte vengono utilizzate per archiviare, recuperare, manipolare e comunicare dati aggregati. In genere, rappresentano elementi di dati che formano un gruppo naturale, come una mano di poker (una raccolta di carte), una cartella di posta (una raccolta di lettere) o un elenco telefonico (una mappatura di nomi in numeri di telefono).
Perché abbiamo bisogno delle regole di confronto?
Una raccolta consente di ordinare i dati dei caratteri per una determinata lingua utilizzando regole che definiscono la corretta sequenza di caratteri, con opzioni per specificare distinzione tra maiuscole e minuscole, accenti, tipi di caratteri kana, uso di simboli o punteggiatura, larghezza dei caratteri e parola ordinamento.
Qual è la differenza tra utf8_general_ci e utf8_unicode_ci?
In breve: utf8_unicode_ci utilizza l’algoritmo di confronto Unicode come definito negli standard Unicode, mentre utf8_general_ci è un ordinamento più semplice che si traduce in risultati di ordinamento “meno accurati”. Se non ti interessa la correttezza, allora è banale rendere qualsiasi algoritmo infinitamente veloce.
Cos’è la raccolta UTF8?
Un confronto è una proprietà dei tipi di stringa in SQL Server, Azure SQL e Synapse SQL che definisce come confrontare e ordinare le stringhe. Inoltre, descrive la codifica dei dati stringa. Se un nome di confronto in Synapse SQL termina con UTF8, rappresenta le stringhe codificate con lo schema di codifica UTF-8.
Cosa significa UTF-8?
UTF-8 (UCS Transformation Format 8) è la codifica dei caratteri più comune del World Wide Web. Ogni carattere è rappresentato da uno a quattro byte. UTF-8 è retrocompatibile con ASCII e può rappresentare qualsiasi Unicode standardcarattere.
Cosa dovrebbe fare la collazione del database?
La fascicolazione è un insieme di regole che indicano al motore di database come confrontare e ordinare i dati dei caratteri in SQL Server. Le regole di confronto possono essere impostate a diversi livelli in SQL Server.