Memorizza tutti i dati in bit in formato binario. I set di caratteri e le regole di confronto contano solo quando si interroga il database, ovvero quando a MySQL viene chiesto di presentare i dati (come in una clausola select) o di analizzare i dati (come in un operatore like nella clausola where).
Le regole di confronto sono importanti in MySQL?
Memorizza tutti i dati in bit in formato binario. I set di caratteri e le regole di confronto contano solo quando si interroga il database, ovvero quando a MySQL viene chiesto di presentare i dati (come in una clausola select) o di analizzare i dati (come in un operatore like nella clausola where).
Devo usare utf8mb4 o utf8?
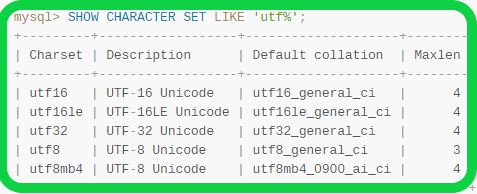
La differenza tra utf8 e utf8mb4 è che il primo può memorizzare solo caratteri a 3 byte, mentre il secondo può memorizzare caratteri a 4 byte. In termini Unicode, utf8 può memorizzare solo caratteri nel piano multilingue di base, mentre utf8mb4 può memorizzare qualsiasi carattere Unicode.
Le regole di confronto influiscono sulle prestazioni?
Se poi specifichi una clausola COLLATE nella query che è diversa dalle regole di confronto utilizzate per l’indice, avrai una riduzione delle prestazioni perché non utilizzerai quell’indice.
Qual è la differenza tra SQL_Latin1_General_CP1_CI_AS e Latin1_General_CI_AS?
Il confronto SQL_Latin1_General_CP1_CI_AS è un confronto SQL e le regole relative all’ordinamento dei dati Unicode e non Unicode sono diverse. Il confronto Latin1_General_CI_AS è un confronto di Windows e le regole relative all’ordinamento dei dati Unicode e non Unicode sono le stesse.
Cos’è il confronto predefinito SQL?
Le regole di confronto predefinite a livello di server sono SQL_Latin1_General_CP1_CI_AS. Se si esegue la migrazione dei database da SQL Server a Istanza gestita, controllare le regole di confronto del server nel SQL Server di origine utilizzando la funzione SERVERPROPERTY(N’Collation’) e creare un’istanza gestita che corrisponda alconfronto del tuo SQL Server.
MySQL 5.7 supporta utf8mb4_0900_ai_ci?
utf8mb4_0900_ai_ci è implementato solo a partire da MySQL 8.0, quindi il server 5.7 non lo riconosce. Poiché il server 5.7 non riconosce utf8mb4_0900_ai_ci , non è in grado di soddisfare la richiesta del set di caratteri del client e torna al set di caratteri e alle regole di confronto predefiniti ( latin1 e latin1_swedish_ci ).
Cosa sono i tipi di regole di confronto MySQL?
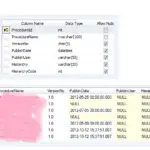
Una raccolta è un insieme di regole che definisce come confrontare e ordinare le stringhe di caratteri. Ogni collation in MySQL appartiene a un singolo set di caratteri. Ogni set di caratteri ha almeno un confronto e la maggior parte ha due o più regole di confronto. Una raccolta ordina i caratteri in base al peso.
A cosa serve fascicolare SQL_Latin1_General_CP1_CI_AS?
La clausola collate viene utilizzata per ricerche con distinzione tra maiuscole e minuscole nelle colonne del server SQL. Sono presenti due tipi di clausola fascicolazione: SQL_Latin1_General_CP1_CS_AS per la distinzione tra maiuscole e minuscole. SQL_Latin1_General_CP1_CI_AS per maiuscole e minuscole.
Le regole di confronto sono importanti in SQL?
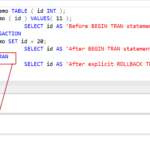
I dati seguono sempre le regole dei vincoli di confronto, configurate durante la creazione di un oggetto. Quando si recuperano i dati utilizzando una query T-SQL, le regole di confronto svolgono un ruolo fondamentale nell’esecuzione. È importante quale confronto è associato a una colonna quando la clausola di ordinamento viene applicata a quella colonna.
Perché UTF-8 è il migliore?
Utilizzando meno spazio per rappresentare caratteri più comuni (ad es. caratteri ASCII), UTF-8 riduce le dimensioni del file pur consentendo un numero molto maggiore di caratteri meno comuni. Questi caratteri meno comuni sono codificati in due o più byte, ma va bene se vengono archiviati con parsimonia.
UTF-8 è migliore di Latin1?
C’è un motivo per cui UTF8 è stato creato, evoluto e promossosoprattutto ovunque: se implementato correttamente, funziona molto meglio. Esistono alcuni problemi di prestazioni e archiviazione derivanti dal fatto che un carattere Latin1 è di 8 bit, mentre un carattere UTF8 può essere lungo da 8 a 32 bit.
Cosa c’è di meglio di UTF-8?
UTF-16 è migliore dove ASCII non è predominante, poiché utilizza principalmente 2 byte per carattere. UTF-8 inizierà a utilizzare 3 o più byte per i caratteri di ordine superiore, mentre UTF-16 rimane a soli 2 byte per la maggior parte dei caratteri. UTF-32 coprirà tutti i caratteri possibili in 4 byte.
Qual è la differenza tra SQL_Latin1_General_CP1_CI_AS e Latin1_General_CI_AS?
Il confronto SQL_Latin1_General_CP1_CI_AS è un confronto SQL e le regole relative all’ordinamento dei dati Unicode e non Unicode sono diverse. Il confronto Latin1_General_CI_AS è un confronto di Windows e le regole relative all’ordinamento dei dati Unicode e non Unicode sono le stesse.
Cos’è il tipo di confronto in MySQL?
Una raccolta è un insieme di regole che definisce come confrontare e ordinare le stringhe di caratteri. Ogni collation in MySQL appartiene a un singolo set di caratteri. Ogni set di caratteri ha almeno un confronto e la maggior parte ha due o più regole di confronto. Una raccolta ordina i caratteri in base al peso.
Cos’è la collazione del database MySQL?
Una collazione MySQL è un insieme ben definito di regole che vengono utilizzate per confrontare i caratteri di un particolare set di caratteri utilizzando la codifica corrispondente. Ogni set di caratteri in MySQL potrebbe avere più di un confronto e almeno un confronto predefinito. Due set di caratteri non possono avere le stesse regole di confronto.
A cosa serve fascicolare SQL_Latin1_General_CP1_CI_AS?
La clausola collate viene utilizzata per ricerche con distinzione tra maiuscole e minuscole nelle colonne del server SQL. Ci sono due tipi diclausola collate presente: SQL_Latin1_General_CP1_CS_AS per la distinzione tra maiuscole e minuscole. SQL_Latin1_General_CP1_CI_AS per maiuscole e minuscole.
Perché abbiamo bisogno delle regole di confronto?
Una raccolta consente di ordinare i dati dei caratteri per una determinata lingua utilizzando regole che definiscono la corretta sequenza di caratteri, con opzioni per specificare distinzione tra maiuscole e minuscole, accenti, tipi di caratteri kana, uso di simboli o punteggiatura, larghezza dei caratteri e parola ordinamento.
Perché usiamo la collazione?
Le raccolte vengono utilizzate per archiviare, recuperare, manipolare e comunicare dati aggregati. In genere, rappresentano elementi di dati che formano un gruppo naturale, come una mano di poker (una raccolta di carte), una cartella di posta (una raccolta di lettere) o un elenco telefonico (una mappatura di nomi in numeri di telefono).
Perché si usa la collazione?
Le regole di confronto in SQL Server forniscono regole di ordinamento, maiuscole e minuscole e proprietà di sensibilità all’accento per i dati. Le regole di confronto utilizzate con i tipi di dati carattere, come char e varchar, determinano la tabella codici e i caratteri corrispondenti che possono essere rappresentati per quel tipo di dati.
Quale motore MySQL è più veloce?
Cos’è InnoDB? InnoDB si è evoluto dall’essere un sottosistema di archiviazione a un motore di archiviazione generico per MySQL. Grazie alla sua combinazione di alte prestazioni e alta affidabilità, è diventato il motore di archiviazione predefinito dalla versione 5.6 in poi.
Qual è MySQL 5.6 o 5.7 più veloce?
MySQL 5.7 è 3 volte più veloce di MySQL 5.6, fornendo 1,6 milioni di query SQL al secondo.