Anúncios
A ordenação SQL_Latin1_General_CP1_CI_AS é uma ordenação SQL e as regras sobre classificação de dados para dados unicode e não-unicode são diferentes. O agrupamento Latin1_General_CI_AS é um agrupamento do Windows e as regras sobre classificação de dados unicode e não-unicode são as mesmas.
Qual é a diferença entre SQL_Latin1_General_CP1_CI_AS e Latin1_General_CI_AS?
O agrupamento SQL_Latin1_General_CP1_CI_AS é um agrupamento SQL e as regras sobre classificação de dados para dados unicode e não-unicode são diferentes. O agrupamento Latin1_General_CI_AS é um agrupamento do Windows e as regras sobre classificação de dados unicode e não-unicode são as mesmas.
Anúncios
O que significa As no agrupamento padrão SQL_Latin1_General_CP1_CI_AS?
O agrupamento do servidor é especificado durante a instalação do SQL Server. O agrupamento de nível de servidor padrão é baseado na localidade do sistema operacional. Por exemplo, o agrupamento padrão para sistemas que usam inglês dos EUA (en-US) é SQL_Latin1_General_CP1_CI_AS.
Como altero meu agrupamento padrão no banco de dados?
Definir ou alterar o agrupamento do banco de dados usando o SSMS Se você estiver criando um novo banco de dados, clique com o botão direito do mouse em Bancos de dados e selecione Novo banco de dados. Se você não quiser o agrupamento padrão, selecione a página Opções e selecione um agrupamento na lista suspensa Agrupamento.
Anúncios
Como encontro o agrupamento SQL?
Você pode obter o agrupamento do servidor no SQL Server Management Studio (SSMS) clicando com o botão direito do mouse na instância do SQL, clicando na opção “Propriedades” e marcando a guia “Geral”. Este agrupamento é selecionado por padrão na instalação do SQL Server.
Qual agrupamento devo usar para o SQL Server?
Collation em nível de servidor para Microsoft SQL Server Se você não escolher um agrupamento diferente, o agrupamento em nível de servidoro padrão é SQL_Latin1_General_CP1_CI_AS. O agrupamento do servidor é aplicado por padrão a todos os bancos de dados e objetos de banco de dados. Você não pode alterar o agrupamento ao restaurar de um snapshot de banco de dados.
Como encontro meu agrupamento de banco de dados padrão?
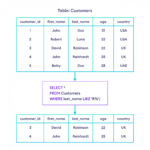
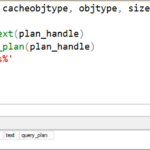
Para exibir a configuração de agrupamento de um banco de dados No Pesquisador de Objetos, conecte-se a uma instância do Mecanismo de Banco de Dados e, na barra de ferramentas, clique em Nova Consulta. Na janela de consulta, insira a seguinte instrução que usa a propriedade sys. visualização do catálogo do sistema de bancos de dados. SELECT nome, collation_name FROM sys.
O que é página de código para SQL_Latin1_General_CP1_CI_AS?
Use qualquer página de código: “Latin1_General_CI_AS” “SQL_Latin1_General_CP1_CI_AS” (CP 1252)
O que é collate latin1_general_ci_as no SQL Server?
A cláusula collate é usada para pesquisas com e sem distinção entre maiúsculas e minúsculas nas colunas do servidor SQL. Há dois tipos de cláusula de agrupamento presentes: SQL_Latin1_General_CP1_CS_AS para distinção entre maiúsculas e minúsculas. SQL_Latin1_General_CP1_CI_AS para não diferenciar maiúsculas de minúsculas.
Qual agrupamento é melhor no MySQL?
Se você optar por usar UTF-8 como seu agrupamento, sempre use utf8mb4 (especificamente utf8mb4_unicode_ci). Você não deve usar UTF-8 porque o UTF-8 do MySQL é diferente da codificação UTF-8 adequada. Isso ocorre porque ele não oferece suporte total a Unicode, o que pode levar à perda de dados ou problemas de segurança.
Qual é o problema de agrupamento no SQL Server?
Os agrupamentos no SQL Server fornecem regras de classificação, maiúsculas e minúsculas e propriedades de diferenciação de acentos para seus dados. Os agrupamentos usados com tipos de dados de caracteres, como char e varchar, determinam a página de código e os caracteres correspondentes que podem ser representados para esse tipo de dados.
O SQL_Latin1_General_CP1_CI_AS está obsoleto?
Qual agrupamento é melhor no MySQL?
Se você optar por usarUTF-8 como seu agrupamento, sempre use utf8mb4 (especificamente utf8mb4_unicode_ci). Você não deve usar UTF-8 porque o UTF-8 do MySQL é diferente da codificação UTF-8 adequada. Isso ocorre porque ele não oferece suporte total a Unicode, o que pode levar à perda de dados ou problemas de segurança.
Quais são todos os diferentes tipos de sensibilidade de agrupamento?
As opções associadas a um agrupamento são diferenciação de maiúsculas e minúsculas, diferenciação de acentos, sensibilidade de kana, sensibilidade de largura e sensibilidade do seletor de variação.
O que é agrupamento e exemplo?
: uma refeição leve permitida em dias de jejum no lugar do almoço ou jantar. : uma refeição leve. [Inglês médio, do latim collation-, collatio] : o ato, processo ou resultado de agrupar.
O que deve ser agrupamento de banco de dados?
Collation é um conjunto de regras que informam ao mecanismo de banco de dados como comparar e classificar os dados de caracteres no SQL Server. O agrupamento pode ser definido em diferentes níveis no SQL Server.
O que é o agrupamento padrão do Oracle?
Binary Collation É um agrupamento padrão da sessão de banco de dados para ORDER BY e BETWEEN (e outras operações que suportam classificação linguística) e é definido como ‘binário’ na variável NLS_COMP.
O SQL 1433 é UDP ou TCP?
Por padrão, as portas típicas usadas pelo SQL Server e serviços de mecanismo de banco de dados associados são: TCP 1433, 4022, 135, 1434, UDP 1434.
Como você remove as dependências no agrupamento do banco de dados e repete a operação?
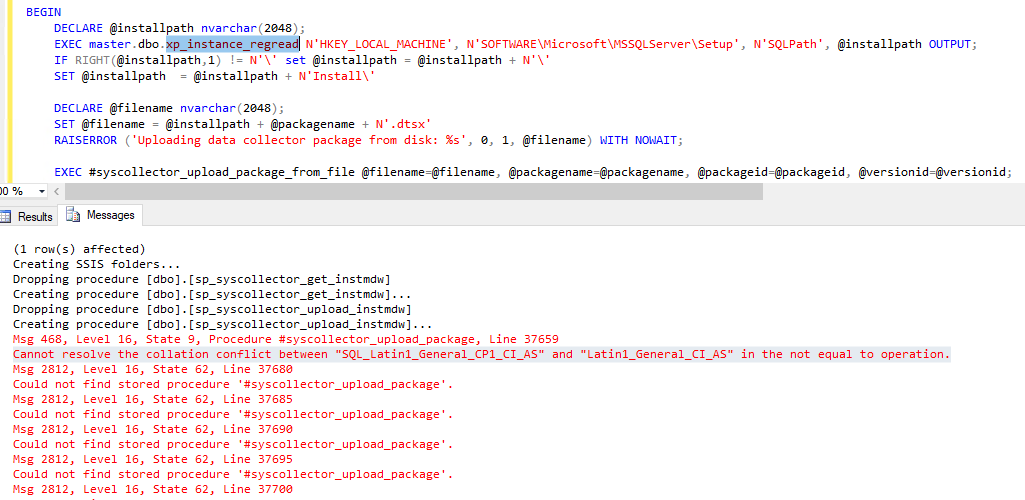
Remova as dependências no agrupamento do banco de dados e repita a operação. No caso acima, parece que há um CHECK CONSTRAINT dependente do agrupamento do banco de dados. Prossiga com o script dos objetos dependentes, elimine os objetos, altere o agrupamento do banco de dados e recrie os objetos dos scripts.
O agrupamento afeta o desempenho?
Se você especificar uma cláusula COLLATE na consulta que seja diferente do agrupamento usado para o índice, haverá uma penalidade de desempenho porque não usará esse índice.
O que é agrupamento padrão Using_nls_comp?
Se nenhum agrupamento for especificado, diretamente ou por meio de uma configuração padrão, o pseudoagrupamento padrão USING_NLS_COMP será usado, o que significa que os parâmetros NLS_SORT e NLS_COMP serão usados para determinar o agrupamento real usado. O único agrupamento com suporte para colunas CLOB e NCLOB é o pseudoagrupamento USING_NLS_COMP.