Os agrupamentos no SQL Server fornecem regras de classificação, maiúsculas e minúsculas e propriedades de diferenciação de acentos para seus dados. Os agrupamentos usados com tipos de dados de caracteres, como char e varchar, determinam a página de código e os caracteres correspondentes que podem ser representados para esse tipo de dados.
O que é erro de agrupamento no SQL?
O que é agrupamento de servidores no SQL Server?
A ordenação no SQL Server é um conjunto predefinido de regras que determinam como os dados são salvos, acessados e comparados. Em outras palavras, é uma definição de configuração que indica como o mecanismo de banco de dados deve lidar com dados de caracteres.
O que é agrupar SQL_Latin1_General_CP1_CI_AS no SQL Server?
A cláusula collate é usada para pesquisas com e sem distinção entre maiúsculas e minúsculas nas colunas do servidor SQL. Há dois tipos de cláusula de agrupamento presentes: SQL_Latin1_General_CP1_CS_AS para distinção entre maiúsculas e minúsculas. SQL_Latin1_General_CP1_CI_AS para não diferenciar maiúsculas de minúsculas.
Como obtenho agrupamento no SQL Server?
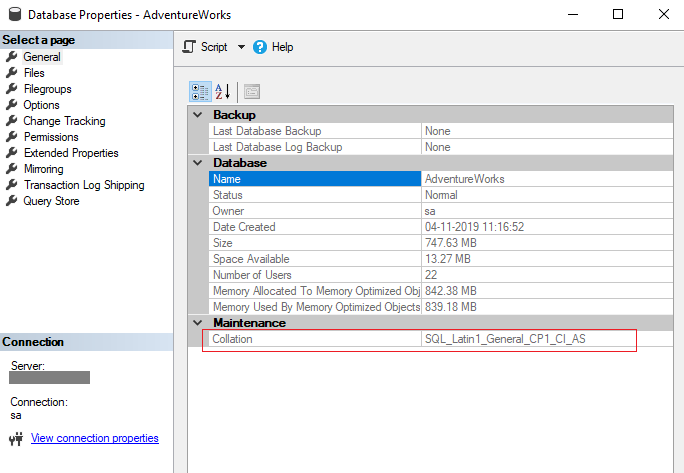
Para exibir a configuração de agrupamento de um banco de dados No Pesquisador de Objetos, conecte-se a uma instância do Mecanismo de Banco de Dados e, na barra de ferramentas, clique em Nova Consulta. Na janela de consulta, insira a seguinte instrução que usa a propriedade sys. visualização do catálogo do sistema de bancos de dados. SELECT nome, collation_name FROM sys.
O que é erro de agrupamento no SQL?
Como altero o agrupamento no SQL?
Como alternativa, se o banco de dados já existir, clique com o botão direito do mouse no banco de dados desejado e selecione Propriedades. Selecione a página Opções e selecione um agrupamento na lista suspensa Agrupamento. Depois de terminar, selecione OK.
O agrupamento afeta o desempenho?
Se você especificar uma cláusula COLLATE na consulta que seja diferente do agrupamento usado para o índice, haverá uma penalidade de desempenho porque vocênão usará esse índice.
Qual é a diferença entre Latin1_General_CI_AS e SQL_Latin1_General_CP1_CI_AS?
O agrupamento SQL_Latin1_General_CP1_CI_AS é um agrupamento SQL e as regras sobre classificação de dados para dados unicode e não-unicode são diferentes. O agrupamento Latin1_General_CI_AS é um agrupamento do Windows e as regras sobre classificação de dados unicode e não-unicode são as mesmas.
O que significa agrupamento no banco de dados?
Collation é um conjunto de regras que informam ao mecanismo de banco de dados como comparar e classificar os dados de caracteres no SQL Server. O agrupamento pode ser definido em diferentes níveis no SQL Server.
O que é o processo de agrupamento?
Collation é a montagem de informações escritas em uma ordem padrão. Muitos sistemas de agrupamento são baseados em ordem numérica ou ordem alfabética, ou extensões e combinações dos mesmos. O agrupamento é um elemento fundamental da maioria dos sistemas de arquivamento de escritórios, catálogos de bibliotecas e livros de referência.
O que são %d e %s em SQL?
Você deve usar %d para valores inteiros e %s para valores string. Você também pode usar %f para um valor de ponto flutuante, %b para dados binários e %% apenas para inserir um símbolo de porcentagem.
Por que o agrupamento é usado?
Os agrupamentos no SQL Server fornecem regras de classificação, maiúsculas e minúsculas e propriedades de diferenciação de acentos para seus dados. Os agrupamentos usados com tipos de dados de caracteres, como char e varchar, determinam a página de código e os caracteres correspondentes que podem ser representados para esse tipo de dados.
Por que usamos agrupamento?
Você pode usar a cláusula COLLATE para aplicar uma expressão de caractere a um determinado agrupamento. Literais de caracteres e variáveis são atribuídos ao agrupamento padrão do banco de dados atual. As referências de coluna são atribuídas ao agrupamento de definição da coluna.
Qual é a diferença entreLatin1_General_CI_AS e SQL_Latin1_General_CP1_CI_AS?
O agrupamento SQL_Latin1_General_CP1_CI_AS é um agrupamento SQL e as regras sobre classificação de dados para dados unicode e não-unicode são diferentes. O agrupamento Latin1_General_CI_AS é um agrupamento do Windows e as regras sobre classificação de dados unicode e não-unicode são as mesmas.
Como corrigir Não é possível resolver o conflito de collation entre SQL_Latin1_General_CP1_CI_AS e Latin1_General_CI_AS na operação igual a?
Problema: não é possível resolver o conflito de agrupamento entre “SQL_Latin1_General_CP1_CI_AS” e “Latin1_General_CI_AS” Basta aplicar o agrupamento padrão aos campos que você está comparando.
O que significa Norecovery em SQL?
NORECOVERY especifica que a reversão não ocorrerá. Isso permite rolar para frente para continuar com a próxima instrução na sequência. Nesse caso, a sequência de restauração pode restaurar outros backups e avançá-los.
O que é erro de agrupamento no SQL?
Qual é o melhor agrupamento para MySQL?
Se você optar por usar UTF-8 como seu agrupamento, sempre use utf8mb4 (especificamente utf8mb4_unicode_ci). Você não deve usar UTF-8 porque o UTF-8 do MySQL é diferente da codificação UTF-8 adequada. Isso ocorre porque ele não oferece suporte total a Unicode, o que pode levar à perda de dados ou problemas de segurança.
O SQL_Latin1_General_CP1_CI_AS diferencia maiúsculas de minúsculas?
Collation de banco de dados Por exemplo, o agrupamento padrão no nível do servidor no SQL Server para a localidade da máquina “Inglês (Estados Unidos)” é SQL_Latin1_General_CP1_CI_AS , que é um agrupamento que não diferencia maiúsculas de minúsculas e diferencia acentos.
Como corrigir Não é possível resolver o conflito de collation entre SQL_Latin1_General_CP1_CI_AS e Latin1_General_CI_AS na operação igual a?
Problema: não é possível resolver o conflito de agrupamentoentre “SQL_Latin1_General_CP1_CI_AS” e “Latin1_General_CI_AS” Basta aplicar o agrupamento padrão aos campos que você está comparando.
Qual é a diferença entre Vachar e Nvarchar?
A principal diferença entre varchar e nvarchar é a maneira como eles são armazenados, varchar é armazenado como dados regulares de 8 bits (1 byte por caractere) e nvarchar armazena dados em 2 bytes por caractere. Por esse motivo, o nvarchar pode conter até 4.000 caracteres e ocupa o dobro do espaço que o SQL varchar.