The SQL_Latin1_General_CP1_CI_AS collation is a SQL collation and the rules around sorting data for unicode and non-unicode data are different. The Latin1_General_CI_AS collation is a Windows collation and the rules around sorting unicode and non-unicode data are the same.
What does SQL_Latin1_General_CP1_CI_AS mean?
The collate clause is used for case sensitive and case insensitive searches in the columns of the SQL server. There are two types of collate clause present: SQL_Latin1_General_CP1_CS_AS for case sensitive. SQL_Latin1_General_CP1_CI_AS for case insensitive.
Is SQL_Latin1_General_CP1_CI_AS deprecated?
Is Latin1_General_CI_AS case sensitive?
In SQL Server, collation options are specified by appending the options to the collation name. So for example, Latin1_General_CI_AS is case-insensitive and accent-sensitive.
What collation should I use for SQL Server?
Server-level collation for Microsoft SQL Server If you don’t choose a different collation, the server-level collation defaults to SQL_Latin1_General_CP1_CI_AS. The server collation is applied by default to all databases and database objects.
What character set is SQL_Latin1_General_CP1_CI_AS?
SQL_Latin1_General_CP1_CI_AS = ‘Dictionary order, case-insensitive, for use with 1252 character set.
What is code page for SQL_Latin1_General_CP1_CI_AS?
Use either code page: “Latin1_General_CI_AS” “SQL_Latin1_General_CP1_CI_AS” (CP 1252)
Does collation matter in SQL?
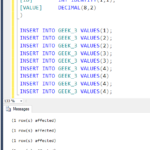
Data always follows collation constraint rules, which are configured when creating an object. When retrieving data using a T-SQL query, collation plays a fundamental role in the execution. It matters which collation is associated with a column when ordering clause is applied to that column.
Can I change SQL Server collation after installation?
The server-level collation for SQL Server Express LocalDB is SQL_Latin1_General_CP1_CI_AS and cannot be changed, either during or after installation.
What are all different types of collation sensitivity?
The options associated with a collation are case sensitivity, accent sensitivity, kana sensitivity, width sensitivity, and variation-selector sensitivity.
What is Oracle default collation?
Binary Collation It’s a default collation of the database session for ORDER BY and BETWEEN (and other operations that support linguistic sort) and is set as ‘binary’ in NLS_COMP variable.
Should Guids be upper or lower case?
The Guid itself is actually a 128-bit integer value and the string is a hexadecimal representation of the same value and hexadecimal is not case sensitive.
Does collation affect performance?
If you then specify a COLLATE clause in the query that is different than the collation used for the index, you will have a performance penalty because you won’t be using that index.
Which collation is best in MySQL?
If you elect to use UTF-8 as your collation, always use utf8mb4 (specifically utf8mb4_unicode_ci). You should not use UTF-8 because MySQL’s UTF-8 is different from proper UTF-8 encoding. This is the case because it doesn’t offer full unicode support which can lead to data loss or security issues.
What does a %’ mean in SQL?
The SQL LIKE Operator The percent sign (%) represents zero, one, or multiple characters. The underscore sign (_) represents one, single character.
Why is collation used?
Collations in SQL Server provide sorting rules, case, and accent sensitivity properties for your data. Collations that are used with character data types, such as char and varchar, dictate the code page and corresponding characters that can be represented for that data type.
Why do we use collation?
Collections are used to store, retrieve, manipulate, and communicate aggregate data. Typically, they represent data items that form a natural group, such as a poker hand (a collection of cards), a mail folder (a collection of letters), or a telephone directory (a mapping of names to phone numbers).
Why do we need collation?
A collation allows character data for a given language to be sorted using rules that define the correct character sequence, with options for specifying case-sensitivity, accent marks, kana character types, use of symbols or punctuation, character width, and word sorting.
What is the difference between utf8_general_ci and utf8_unicode_ci?
In short: utf8_unicode_ci uses the Unicode Collation Algorithm as defined in the Unicode standards, whereas utf8_general_ci is a more simple sort order which results in “less accurate” sorting results. If you don’t care about correctness, then it’s trivial to make any algorithm infinitely fast.
What is UTF8 collation?
A collation is a property of string types in SQL Server, Azure SQL, and Synapse SQL that defines how to compare and sort strings. In addition, it describes the encoding of string data. If a collation name in Synapse SQL ends with UTF8, it represents the strings encoded with the UTF-8 encoding schema.
What UTF-8 means?
UTF-8 (UCS Transformation Format 8) is the World Wide Web’s most common character encoding. Each character is represented by one to four bytes. UTF-8 is backward-compatible with ASCII and can represent any standard Unicode character.
What should database collation?
Collation is a set of rules that tell database engine how to compare and sort the character data in SQL Server. Collation can be set at different levels in SQL Server.