Η ταξινόμηση SQL_Latin1_General_CP1_CI_AS είναι μια ταξινόμηση SQL και οι κανόνες σχετικά με την ταξινόμηση δεδομένων για δεδομένα unicode και μη unicode είναι διαφορετικοί. Η ταξινόμηση Latin1_General_CI_AS είναι μια ταξινόμηση των Windows και οι κανόνες σχετικά με την ταξινόμηση δεδομένων unicode και non-unicode είναι οι ίδιοι.
Τι σημαίνει SQL_Latin1_General_CP1_CI_AS;
Η ρήτρα ταξινόμησης χρησιμοποιείται για αναζητήσεις με διάκριση πεζών-κεφαλαίων και πεζών-κεφαλαίων στις στήλες του διακομιστή SQL. Υπάρχουν δύο τύποι ρήτρας ταξινόμησης: SQL_Latin1_General_CP1_CS_AS για διάκριση πεζών-κεφαλαίων. SQL_Latin1_General_CP1_CI_AS για διάκριση πεζών-κεφαλαίων.
Το SQL_Latin1_General_CP1_CI_AS έχει καταργηθεί;
Είναι το Latin1_General_CI_AS διάκριση πεζών-κεφαλαίων;
Στον SQL Server, οι επιλογές ταξινόμησης καθορίζονται με την προσθήκη των επιλογών στο όνομα της ταξινόμησης. Έτσι, για παράδειγμα, το Latin1_General_CI_AS είναι χωρίς διάκριση πεζών-κεφαλαίων και ευαίσθητο στον τόνο.
Τι ταξινόμηση πρέπει να χρησιμοποιήσω για τον SQL Server;
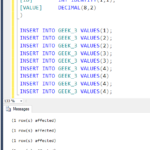
Σαρρύθμιση σε επίπεδο διακομιστή για Microsoft SQL Server Εάν δεν επιλέξετε διαφορετική ταξινόμηση, η ταξινόμηση σε επίπεδο διακομιστή ορίζεται από προεπιλογή σε SQL_Latin1_General_CP1_CI_AS. Η ταξινόμηση διακομιστή εφαρμόζεται από προεπιλογή σε όλες τις βάσεις δεδομένων και τα αντικείμενα βάσης δεδομένων.
Τι σύνολο χαρακτήρων είναι το SQL_Latin1_General_CP1_CI_AS;
SQL_Latin1_General_CP1_CI_AS = ‘Σειρά λεξικού, χωρίς διάκριση πεζών-κεφαλαίων, για χρήση με σύνολο χαρακτήρων 1252.
Τι είναι η κωδικοσελίδα για το SQL_Latin1_General_CP1_CI_AS;
Χρησιμοποιήστε οποιαδήποτε σελίδα κώδικα: “Latin1_General_CI_AS” “SQL_Latin1_General_CP1_CI_AS” (CP 1252)
Έχει σημασία η ταξινόμηση στην SQL;
Τα δεδομένα ακολουθούν πάντα τους κανόνες περιορισμού ταξινόμησης, οι οποίοι διαμορφώνονται κατά τη δημιουργία ενός αντικειμένου. Κατά την ανάκτηση δεδομένων χρησιμοποιώντας ένα ερώτημα T-SQL, η ταξινόμηση διαδραματίζει θεμελιώδη ρόλο στην εκτέλεση. Έχει σημασία ποια ταξινόμηση σχετίζεται με μια στήλη κατά την παραγγελία ρήτραςεφαρμόζεται σε αυτήν τη στήλη.
Μπορώ να αλλάξω τη ταξινόμηση του SQL Server μετά την εγκατάσταση;
Η ταξινόμηση σε επίπεδο διακομιστή για το SQL Server Express LocalDB είναι SQL_Latin1_General_CP1_CI_AS και δεν μπορεί να αλλάξει, είτε κατά τη διάρκεια είτε μετά την εγκατάσταση.
Ποιοι είναι όλοι οι διαφορετικοί τύποι ευαισθησίας ταξινόμησης;
Οι επιλογές που σχετίζονται με μια σελιδοποίηση είναι η ευαισθησία πεζών-κεφαλαίων, η ευαισθησία τονισμού, η ευαισθησία kana, η ευαισθησία πλάτους και η ευαισθησία επιλογέα παραλλαγής.
Τι είναι η προεπιλεγμένη ταξινόμηση της Oracle;
Δυαδική Συρρύθμιση Είναι μια προεπιλεγμένη ταξινόμηση της περιόδου σύνδεσης της βάσης δεδομένων για ORDER BY and BETWEEN (και άλλες λειτουργίες που υποστηρίζουν γλωσσική ταξινόμηση) και ορίζεται ως “δυαδική” στη μεταβλητή NLS_COMP.
Οι οδηγοί πρέπει να είναι κεφαλαίοι ή πεζοί;
Ο ίδιος ο Οδηγός είναι στην πραγματικότητα μια ακέραια τιμή 128-bit και η συμβολοσειρά είναι μια δεκαεξαδική αναπαράσταση της ίδιας τιμής και το δεκαεξαδικό δεν κάνει διάκριση πεζών-κεφαλαίων.
Επηρεάζει η ταξινόμηση την απόδοση;
Εάν στη συνέχεια καθορίσετε μια ρήτρα COLLATE στο ερώτημα που είναι διαφορετική από τη συγκρότηση που χρησιμοποιείται για το ευρετήριο, θα έχετε μια ποινή απόδοσης επειδή δεν θα χρησιμοποιείτε αυτό το ευρετήριο.
Ποια ταξινόμηση είναι καλύτερη στη MySQL;
Εάν επιλέξετε να χρησιμοποιήσετε το UTF-8 ως συρραφή, χρησιμοποιήστε πάντα το utf8mb4 (συγκεκριμένα utf8mb4_unicode_ci). Δεν πρέπει να χρησιμοποιείτε το UTF-8 επειδή το UTF-8 της MySQL είναι διαφορετικό από την κατάλληλη κωδικοποίηση UTF-8. Αυτό συμβαίνει επειδή δεν προσφέρει πλήρη υποστήριξη unicode που μπορεί να οδηγήσει σε απώλεια δεδομένων ή ζητήματα ασφάλειας.
Τι σημαίνει το %’ στην SQL;
Ο χειριστής SQL LIKE Το σύμβολο ποσοστού (%) αντιπροσωπεύει μηδέν, έναν ή πολλούς χαρακτήρες. Το σύμβολο υπογράμμισης (_) αντιπροσωπεύει έναν, μοναδικό χαρακτήρα.
Γιατί χρησιμοποιείται η ταξινόμηση;
Οι συλλογές στον SQL Server παρέχουν κανόνες ταξινόμησης, πεζών-κεφαλαίων και ιδιότητες ευαισθησίας έμφασης γιαδεδομένα. Οι συλλογές που χρησιμοποιούνται με τύπους δεδομένων χαρακτήρων, όπως char και varchar, υπαγορεύουν την κωδικοσελίδα και τους αντίστοιχους χαρακτήρες που μπορούν να αναπαρασταθούν για αυτόν τον τύπο δεδομένων.
Γιατί χρησιμοποιούμε ταξινόμηση;
Οι συλλογές χρησιμοποιούνται για την αποθήκευση, την ανάκτηση, τον χειρισμό και την επικοινωνία συγκεντρωτικών δεδομένων. Συνήθως, αντιπροσωπεύουν στοιχεία δεδομένων που σχηματίζουν μια φυσική ομάδα, όπως ένα χέρι πόκερ (μια συλλογή από κάρτες), ένα φάκελο αλληλογραφίας (μια συλλογή από γράμματα) ή έναν τηλεφωνικό κατάλογο (μια αντιστοίχιση ονομάτων σε αριθμούς τηλεφώνου).
Γιατί χρειαζόμαστε αντιπαραβολή;
Μια συλλογή επιτρέπει την ταξινόμηση των δεδομένων χαρακτήρων για μια δεδομένη γλώσσα χρησιμοποιώντας κανόνες που καθορίζουν τη σωστή ακολουθία χαρακτήρων, με επιλογές για τον καθορισμό πεζών-κεφαλαίων, σημαδιών τονισμού, τύπων χαρακτήρων kana, χρήση συμβόλων ή σημείων στίξης, πλάτους χαρακτήρων και λέξης ταξινόμηση.
Ποια είναι η διαφορά μεταξύ utf8_general_ci και utf8_unicode_ci;
Εν συντομία: το utf8_unicode_ci χρησιμοποιεί τον αλγόριθμο συλλογής Unicode όπως ορίζεται στα πρότυπα Unicode, ενώ το utf8_general_ci είναι μια πιο απλή σειρά ταξινόμησης που οδηγεί σε “λιγότερο ακριβή” αποτελέσματα ταξινόμησης. Αν δεν σας ενδιαφέρει η ορθότητα, τότε είναι ασήμαντο να κάνετε οποιονδήποτε αλγόριθμο απείρως γρήγορο.
Τι είναι η ταξινόμηση UTF8;
Μια ταξινόμηση είναι μια ιδιότητα τύπων συμβολοσειρών στον SQL Server, στο Azure SQL και στο Synapse SQL που καθορίζει τον τρόπο σύγκρισης και ταξινόμησης συμβολοσειρών. Επιπλέον, περιγράφει την κωδικοποίηση δεδομένων συμβολοσειράς. Εάν ένα όνομα collation στο Synapse SQL τελειώνει με UTF8, αντιπροσωπεύει τις συμβολοσειρές που κωδικοποιούνται με το σχήμα κωδικοποίησης UTF-8.
Τι σημαίνει UTF-8;
UTF-8 (UCS Transformation Format 8) είναι η πιο κοινή κωδικοποίηση χαρακτήρων του World Wide Web. Κάθε χαρακτήρας αντιπροσωπεύεται από ένα έως τέσσερα byte. Το UTF-8 είναι συμβατό με ASCII και μπορεί να αντιπροσωπεύει οποιοδήποτε τυπικό Unicodeχαρακτήρας.
Τι θα πρέπει να συγκρίνει η βάση δεδομένων;
Η συρραφή είναι ένα σύνολο κανόνων που λένε στη μηχανή βάσης δεδομένων πώς να συγκρίνει και να ταξινομεί τα δεδομένα χαρακτήρων στον SQL Server. Η ταξινόμηση μπορεί να οριστεί σε διαφορετικά επίπεδα στον SQL Server.